WIP Pdf archive managing tool.
The code is available at Github!
https://github.com/SiottoTamat/WPF_PDF_Organizer
This was a Frankenstein project of mine that I finally updated to a more user-friendly UI. In the course of the years I developed a series of small tools to manage pdf files. My collection of research documents is now in the thousands and I needed tools to streamline my work with them.
I developed a series of small programs to help in dealing with the common problems of pdf files. These tools usually did things that you could do with pdf readers, but these readers needed either an abnormal amount of time or a lot of manual work. They were serious bottlenecks for an efficient and streamlined research. I prefer to spend more time on thinking and reading than on doing tedious legwork.
I patched all of these small tools in a single and elegant WPF windows program. For now it looks like below, but it is a work in progress.
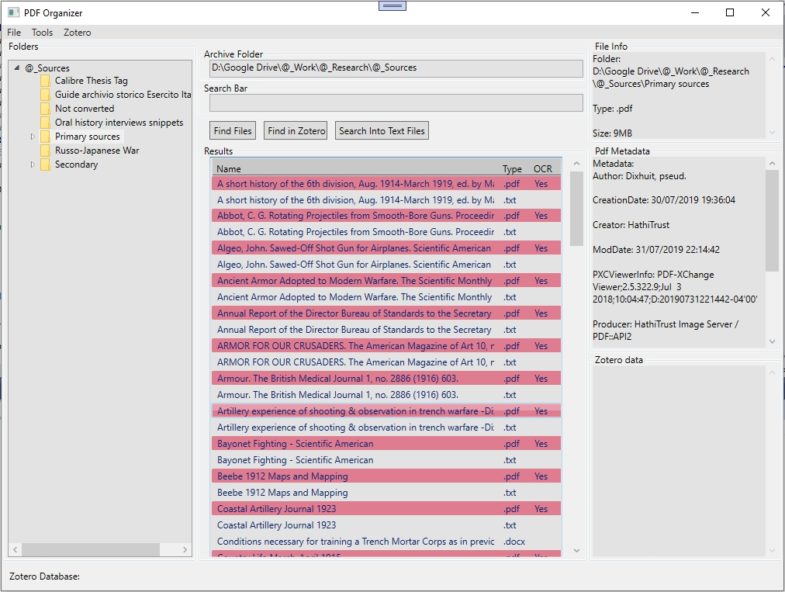
You can choose a directory as your working archive location. In the center is your working area, where the program shows either the files of the selected folder or the result of your search. On the right the program shows the file’s general info: if the file is a pdf it shows the metadata with the addition of the number of pages and a prediction of the presence of OCR in the pdf if the program founds fonts inside the file. I wish that the pdf standard would indicate the presence of text in the pdf, but to my sorrow this seems to be my best option for a fast guess.
I comment my pdfs and highlight them consistently, so it is important for me to have the ability to extract this material. Book reviews and summaries are much easier for me this way. Therefore, I wrote some code to extract these comments in an orderly fashion as a txt file, ordered by page number.
But the important tool here (a later addition to the original program) is the extract all text button. This does precisely what it means. It takes all the text from the pdf document and creates a txt file with all the text in it. Why is this important? Before this tool, when I was looking for something in my documents I used the powerful option of searching the word in all the pdf documents in a folder. When the documents were hundreds however it took hours for every single search. I could export and save it, but every time that I had to search for another thing (which happens pretty often when I am writing an article or a chapter) I had to stop everything and wait for the results. The alternative was to keep writing, but then my stream of reasoning was blocked.
I had to find a different, much faster solution.
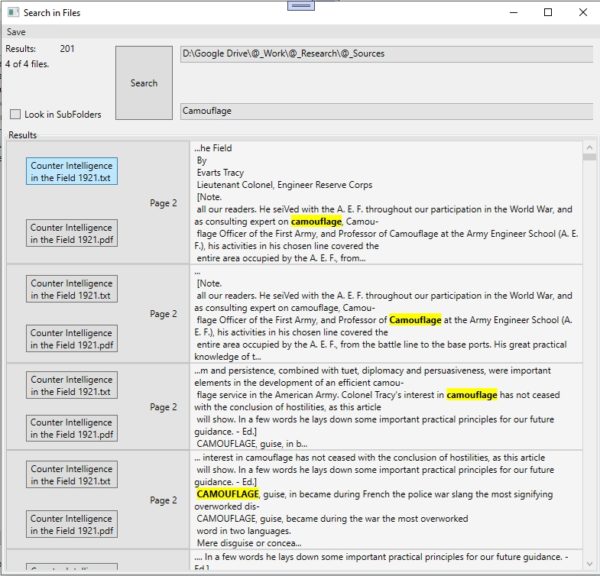
Extracting all the text allowed me to do the same thing that I was doing in the pdf viewer, but in my program (or any good txt editor such as Notepad++). Now it takes seconds to do a research and I can still save my results as a file. This has been an excellent tool for my research and it solved a great deal of problems.
Zotero is my main tool for research, and I wanted to connect to its database without the need to open Zotero all the times. Therefore I inserted a search tool inside my program, and the possibility to show the result on the main window.
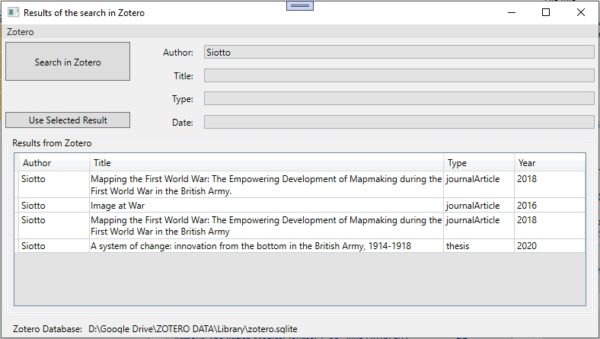
With this too I can see if the file has been already added to Zotero and if that is the case, to show the metadata inside my program.
