AWS Textract / Data Cleaning of the Geographic Names and Locations in the Atlas of the Chinese Empire (1908)¶
Overview¶
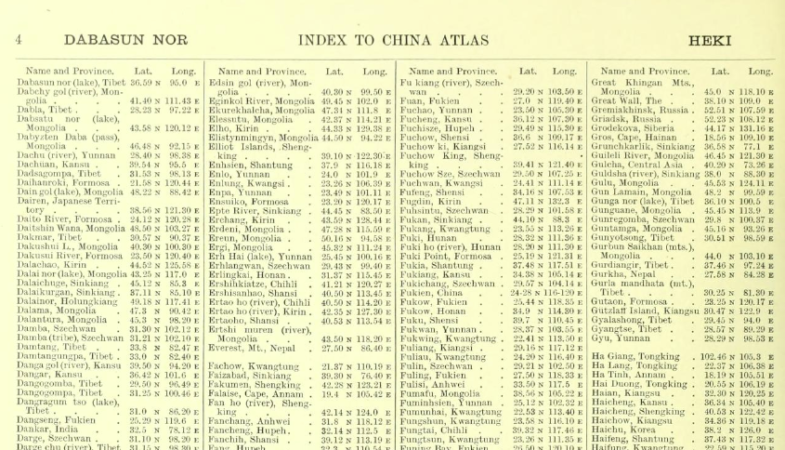
In this project, I used AWS Textract to perform OCR on scanned historical maps and tabular indexes from the Atlas of the Chinese Empire (1908), published by Edward Stanford for the Chinese Imperial Maritime Customs Service.
My goal was to extract, clean, and structure geographic names and coordinate data from printed historical sources into modern, analyzable formats such as CSV and JSON. This work contributes to historical GIS and digital humanities research.
Methodology¶
- Input Data:
- High-resolution scans of tabular indexes and maps.
-
Source material included geographic names, administrative areas, and coordinates.
-
OCR with AWS Textract:
- I used Textract to extract structured tables and key-value pairs from the scanned pages.
-
I focused on index pages and legend sections for maximum data density.
-
Post-processing:
- I wrote custom Python scripts to clean and normalize the extracted text.
- I standardized geographic names and converted coordinates into decimal format.
-
Where possible, I added country codes and contextual metadata for historical relevance.
-
Validation:
- I cross-referenced results with both historical and modern gazetteers.
- For ambiguous or incomplete entries, I manually reviewed and corrected data.
Example Outputs¶
The project produced structured datasets that include:
- original_name, country, coordinates, rank, place_type, and classification flags.
- Geo-referenced outputs ready for direct use in GIS platforms.
- Annotated screenshots of the AWS Textract interface showing recognized table structures.
Tools and Technologies¶
- AWS Textract
- Python (
pandas,re,pathlib) - Custom regular expressions for data normalization
- Excel for quality control and manual corrections
- Markdown and HTML for documentation and reporting
Challenges Addressed¶
During the project, I encountered several technical and historical issues:
- Irregular spelling and naming variations across historical documents
- OCR misreads due to dense or degraded print
- Complex nested table layouts requiring tailored parsing
- Sparse metadata, often requiring manual investigation and validation
Impact¶
This work enables integration of early 20th-century geographic information from China into modern digital platforms. It supports research in historical geography, temporal GIS, and the broader field of digital humanities.