Encyclopedia Britannica
During the academic year 2016/17 I was a Fellow at the Digital Scholarship Center of Temple University (now Loretta C. Duckworth Scholars Studio). Half of my time was dedicated to my research, which led to the writing and publication of my article on Mapping during the WWI; the other half I supported the research of Dr. Peter Logan, who was setting up the Nineteenth-Century Knowledge Project.
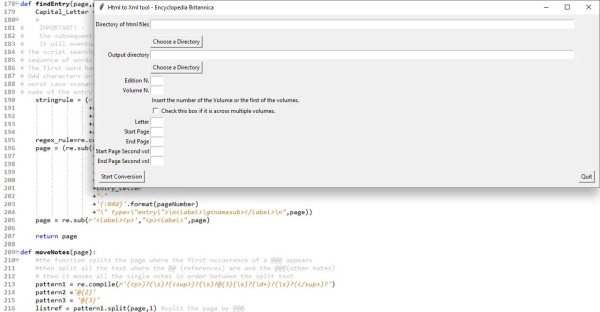
At the time was a highly experimental project and Peter needed to understand how to transform the output of Abbyy Finereader (an Optical Character Recognition program) in XML, the format needed for the data analysis.
There were some complex obstacles to solve:
- How to separate the different Entries of the Encyclopedia
- How to move the notes from the bottom of the page to where the original footnote reference appeared
- How to streamline the pipeline for the OCR process in Abbyy.
My job was to solve these problems. I therefore started to experiment on the different outputs of Abbyy to see which one would have been the best and developed the Python code to find the start of the different entries, check if they were on multiple pages, move the footnotes inside the entry, and export them in single, separate files.
It was a complex task, full of challenges and fun. At the end I had a pipeline and a beefy Python program to export XMLs. The project since has grown in complexity and steps, so I definitely can’t claim that I did all the coding, however I am proud of that I set the first stones of the foundation and to see that some of the solution that I found are still in today’s pipeline. My favorite is the manual insertion of the @@ where there is a footnote in the text and of @@@ at the actual footnotes. In this way the python code that I wrote could safely recognize where the notes are and where to put them (the superscript number was extremely tricky to recognize correctly).
I wonder if whomever have to deal with this method now ever think who chose to use @@ and why. Well, that’s me!
