Not all the archives are following the industry standard for search engines and sharing of results. It is unfortunate but understandable, knowing how much it cost to invest in such programs and how few resources the archives have nowadays.
An historian with some code skills however can develop simple tools to organize manually his research and cut down times. I developed this code to address a problem in the Imperial War Museum website’s research system.
The problem:
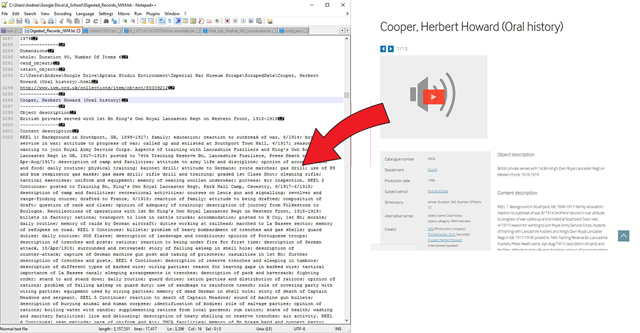
The IWM offers online the possibility to listen the tapes of the oral interviews that they graciously digitized. Every each of them has the name of the interviewed, a brief description of who he/she was and of his/her rank or civilian role, and the description of the content of the different reels. It is a treasure of oral interviews, but has some problems:
- You can’t research if not online and each research takes some time to communicate with the server
- the IWM website is not really user friendly (at least while I am writing)
- I had continual inconsistency in the research and multiple times if I searched for a word that I knew that was in the description of the contents, the page did not pop out.
These problems made any research of any specific topic extremely difficult. For example if I wanted to search for people that talked about bayonets, I had to scroll through a very long list of artifacts, books, and other stuff that was not interesting for me. I wanted to be able to search by word only in the oral interviews of First World War’s veterans.
The solution:
Create a file with all the data from the web pages of the archive well organized and with the links to the pages. In this way I can open my txt file, search by word, go directly to the page that I am interested in, and click on the reel to listen the interview.
How to do it?
The first problem is to be sure that we don’t overload the server with a ton of requests.
I made a search for “oral interview” and “First World War.” The results were hundreds, but they were all collected in not more than 30 pages. I therefore manually saved these pages in a folder on my computer. In this way I could obtain the list of all the pages of the interviews interesting to me manually. (well I wrote a very short Python code to extract them from the pages)
The second step was to write a code that downloaded all the contents of the pages of every single interview. I did dis cautiously, because you don’t want to overload the server with a ton of automatic requests. I put a delay of 3 seconds between each request for this reason. It would have taken hours, but who cares? I simply ran the script in the night.
Once I had all the pages well organized in a folder I could take all the time that I wanted to extract the data from the pages and organize them in a text file as I wished.
This project enabled me to write an article on Mapping during the First World War using the oral histories of the IWM as a foundation for my research. What before would have been extremely difficult and lengthy, with few hours of coding became an easy exercise of searching in a single file, go online, and listen to the interesting bits of interviews. If as it seems now digitization is the future of many archives, coding will be probably considered a basic skill even for historians in the future.
Python Code for organizing from offline web pages to single file
import os
from bs4 import BeautifulSoup
import codecs
def main():
with codecs.open("Digested_Records_IWM.txt","w",encoding='utf-8'):
pass
path =r"C:\Users\Andrea\Google Drive\Aptana Studio Environment\Imperial War Museum Scrape\ScrapedData"
manageFile(path)
def manageFile(totalpath):
for file in os.listdir(totalpath):
longfile =totalpath+"\\"+file
data = codecs.open(longfile,'r', encoding='utf-8').read()
soup = BeautifulSoup(data,'lxml')
region2 = soup.find('div', attrs={'id':'iwm-collections-region-2'})
region3 = soup.find('div', attrs={'id':'iwm-collections-region-3'})
link = soup.find('meta', attrs={'property':'og:url'})['content']
print(link)
with codecs.open("Digested_Records_IWM.txt","a",encoding='utf8') as file:
file.write('<start_object>'+"\n")
file.write(longfile+"\n")
file.write(link+"\n")
file.write("--------------"+"\n")
file.write(soup.find('div', attrs={'class':'page-title'}).text.strip()+"\n")
file.write("--------------"+"\n")
file.write(region3.findAll('h5')[0].text+"\n")
file.write(region3.findAll('p')[0].text+"\n")
file.write("--------------"+"\n")
if len(region3.findAll('p'))>1:
file.write(region3.findAll('h5')[1].text+"\n")
file.write(region3.findAll('p')[1].text+"\n")
#file.write(region3.findAll('h5')[2].text)
file.write("--------------"+"\n")
file.write (region2.findAll('dt')[0].text+"\n")
file.write (region2.findAll('li')[0].text+"\n")
file.write("--------------"+"\n")
file.write(region2.findAll('dt')[2].text+"\n")
file.write(region2.findAll('dd')[2].text.strip()+"\n")
file.write("--------------"+"\n")
file.write(region2.findAll('dt')[4].text+"\n")
file.write (region2.findAll('li')[2].text+"\n")
file.write("<end_object>"+"\n")
if __name__ == '__main__':
main()
